
GPT-4.5判了Scaling Law“死刑”?
【数据猿导读】 这两天,AI界好不热闹。最有看点的,是DeepSeek和OpenAI打擂台。DeepSeek 陆续开源了一些“干货”,得到了大量的好评。而反观OpenAI,则发布了备受瞩目的GPT-4.5,但是从目前情况来看,还是失望多于惊喜。

这两天,AI界好不热闹。最有看点的,是DeepSeek和OpenAI打擂台。DeepSeek 陆续开源了一些“干货”,得到了大量的好评。而反观OpenAI,则发布了备受瞩目的GPT-4.5,但是从目前情况来看,还是失望多于惊喜。
最主要的是,GPT-4.5没能带来人们期望中的模型能力的显著提升,而有点像“挤牙膏”,有一点进步,但不多。关键的是,这点进步的代价却不小。有人对比了一下GPT-4.5和DeepSeek V3的价格,刺激就更大了。

当然,OpenAI是有苦说不出,“不是我贪心,是成本摆在那,就是收你们这个钱,我都还是血亏啊”。
目前,网络上已经出现了很多关于GPT-4.5的使用测评,我们就不多说了。
作为专业媒体,我们讨论一个更本质的问题——GPT-4.5差强人意的表现,是不是意味着Scaling Law就彻底失效了?模型的规模已经触及天花板,以后别想扩大规模这事儿?
这是一个很关键的问题,不同的选择甚至会决定整个行业的走向。
Scaling Law(规模法则)是怎么来的?
以史为鉴,可以知兴替。要看清楚未来的方向,不妨先回望一下来时的路。
人工智能的发展历程是一场技术不断突破、理论不断演化的漫长征程。从20世纪50年代的符号主义人工智能到今天的大规模语言模型,AI的每一次进步都伴随着新思想的诞生和旧理论的修正。
最初的符号主义AI强调逻辑推理与知识表示,它依赖于精确的规则和符号系统,在专家系统的框架下处理特定领域的问题。到了20世纪80年代末至90年代初,机器学习逐渐成为AI领域的新方向。机器学习突破了符号主义的束缚,逐步让计算机能够通过数据学习而非依赖人工编码规则。神经网络,尤其是反向传播算法(backpropagation)的复兴,为AI的发展打开了新的大门。然而,由于计算资源的限制和数据集的匮乏,深度学习尚未成为主流,AI的应用范围依旧局限。
在这段时间,人们脑海中基本还不存在Scaling Law这个概念,大家的专注点都在于算法模型的创新。如果这个时候有人说“单纯扩大模型规模就可以了”,大部分人会骂他是个疯子。
进入21世纪后,深度学习随着大数据和计算能力的提升,迅速崛起。2012年,AlexNet在ImageNet图像识别竞赛中的震撼表现标志着深度学习进入了一个全新时代。随着技术的发展,AI的进步并不仅仅依赖于算法的改进,计算资源的增长和数据的积累也起到了至关重要的作用。大数据的涌现与云计算的普及为AI提供了前所未有的算力支持,这为深度学习的迅猛发展创造了条件。
进入2010年代末,深度学习走向了一个前所未有的高峰。2018年,谷歌推出了Transformer架构,它彻底改变了自然语言处理的格局。Transformer通过自注意力机制(self-attention)能够有效地捕捉序列数据中的长程依赖关系,成功解决了传统RNN和LSTM在长文本处理上的瓶颈。Transformer架构的成功,不仅让自然语言处理进入了一个新的时代,也为大模型的发展奠定了基础。
但是,这个时候离Scaling Law才刚刚有点萌芽,还没成为行业的成为金科玉律。
随着Transformer架构的诞生,基于这一架构的大规模预训练语言模型(如BERT、GPT等)迅速登上了AI的舞台。2019年,OpenAI发布了GPT-2,模型的规模达到了15亿个参数,展示了巨大的潜力。GPT-2在文本生成、语言理解和推理等方面表现出了超乎想象的能力,标志着预训练语言模型的新时代。
然而,GPT-2的成功也引发了对更大规模模型的期待,最终导致了GPT-3的诞生。GPT-3的发布可谓是AI领域的一次革命,它的参数规模达到了1750亿,几乎超越了当时所有同类模型。GPT-3的发布不仅是技术突破,也代表了Scaling Law的成熟。
根据这一法则,规模的扩大带来了模型能力的显著跃升。GPT-3的能力超越了前代所有模型,特别是在生成语言的流畅性、推理能力和少样本学习等方面表现得尤为突出。
GPT-3的成功使得Scaling Law成为AI界广泛接受的“真理”,几乎所有的AI大模型开发者都开始依赖这一法则来指导模型的设计。OpenAI、谷歌、Meta、Anthropic,以及中国的百度、阿里、腾讯、字节跳动、月之暗面、智谱AI等,纷纷加入了大规模预训练模型的开发浪潮。
这个时候,大模型成为了主流技术路线,Scaling Law几乎成为了AI发展的“金科玉律”。
但随着事态的发展,渐渐有不少厂商对Scaling Law提出质疑,越来越多人开始提小模型。需要指出的是,我们觉得,初期很多提小模型的厂商,有不少是自己实力不够强,玩不起这个“烧钱”游戏,但又想早点把自己模型规模没那么大的产品落地,早点赚钱,出于这个目的来混淆视听。
在国外,人们还是比较相信Scaling Law,尤其是谷歌、Meta、微软、亚马逊等巨头,从他们2025年的资本开支就可以看出,他们是准备在今年继续大干一场的。
然而,DeepSeek的横空出世,让人们猛然发现,小一点的模型、更低的成本,实现差不多的模型能力,这条路是可行的,于是国内外的风向开始转变了。再加上这次GPT-4.5差强人意的表现,相信人们对于Scaling Law的质疑又会增加几分。
也许,接下来,人们会从一个极端走向另一个极端,即从将Scaling Law奉为金科玉律,走向彻底抛弃Scaling Law。我们认为,Scaling Law只是遇到了阶段性瓶颈,并没有完全失效。为了说明这个问题,我们先来澄清两个容易误解的地方:
1、大模型的创新,一直是两条腿走路,而Scaling Law只是其中的一条腿;
2、模型规模导致的能力提升,一直都不是线性的。
大模型的路,一直是两条腿在走
大模型的能力提升,实际上一直是一个双重路径的进程。过去,我们看到的是两条腿并行走路:一条腿代表着通过Scaling Law(规模法则)推动模型规模的不断扩展,另一条腿则是通过算法创新与工程优化来提升模型的效率和智能水平。
最初,随着GPT-2、GPT-3的成功,Scaling Law显然走得更快。这一阶段,模型规模的扩展成为了主导力量,几乎所有突破性的进展都来自于规模的急剧膨胀。GPT-3的发布,尤其是其1750亿个参数的模型,几乎是一项革命性的突破,这使得“规模即智能”的理念深入人心。业界普遍相信,模型的规模越大,其表现就会越好,Scaling Law成为了不可动摇的信条。
然而,这并不意味着算法创新与工程优化在此过程中消失。实际上,虽然在前几年里规模扩张这条腿走得更快,算法与架构的优化始终在默默推进。例如,尽管GPT系列在参数数量上不断增加,但同时,OpenAI和其他研究者也在不断对训练算法、优化方法以及模型架构进行改进。包括混合精度训练、模型稀疏化、动态计算路径等技术的引入,都是在为提升大模型效率、减少计算成本而进行的优化尝试。可以说,算法创新和工程优化的“另一条腿”,一直在不断跟进并为大模型的有效扩展提供支撑。
只是,Deepseek的成功,向人们展示了工程优化的效果居然可以这么好。Deepseek的做法表明,AI的突破不仅依赖于“做得更大”,更要注重“做得更好”。这种对效率和创新的追求,促使AI研发者意识到:将来要想持续推动AI能力的突破,必须加大对算法优化和工程创新的投资。模型不再只是参数数量的堆砌,而是要在算法和架构设计上进行更深刻的优化。这也预示着,随着Scaling Law的边际效应渐显,算法创新和工程优化将成为下一阶段AI技术进步的核心。
Scaling Law只是遇到瓶颈,没有完全失效
当我们回顾大模型的进化史,越来越显而易见的一点是:模型的规模扩展并非线性。
最初,从数百万到数亿参数时,模型的性能提升几乎是渐进的。即便是GPT-2,也不过是1.5亿参数的模型,尽管在当时表现不俗,但它离颠覆性的智能突破还差得很远。
只有当模型参数达到数百亿,性能的提升才显得显著,特别是在GPT-3的发布中,当参数数量飙升至1750亿时,模型的表现飞跃至一个新的层次。这个突破显示了一个重要的现象:真正的“智能涌现”,即智能水平的质变,往往并不在模型的每一次扩展中出现,而是在模型规模达到某个临界点后突然爆发。
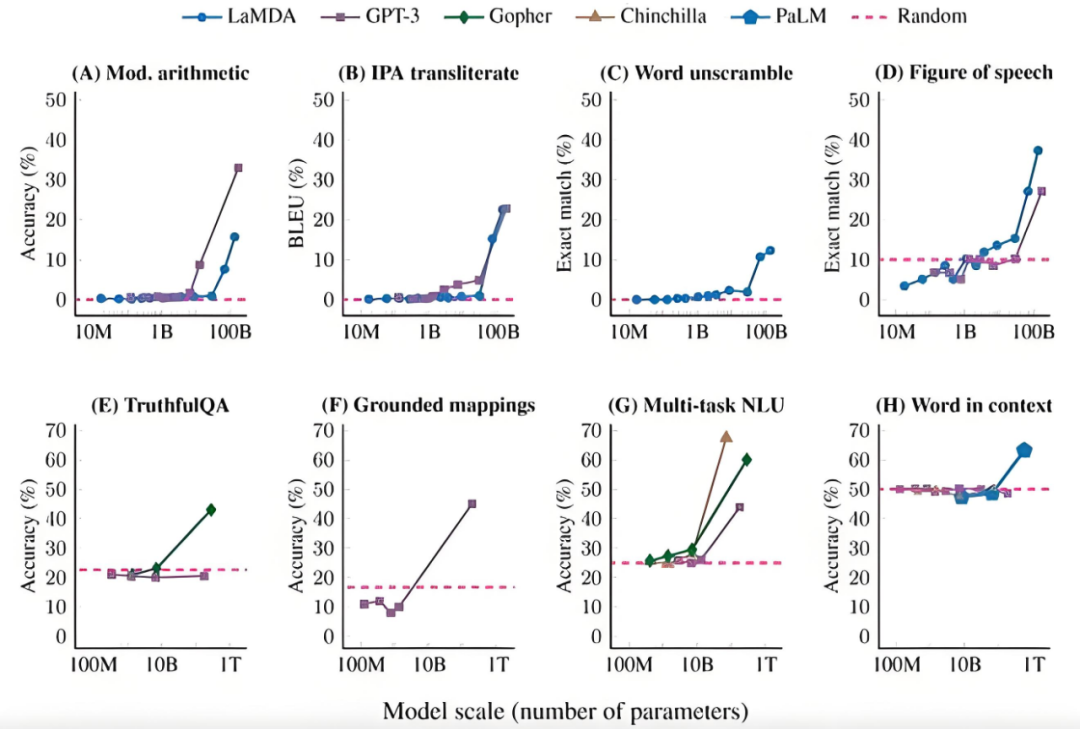
在达到700亿参数左右时,模型的推理能力、语言理解能力以及生成能力都有了质的飞跃。这是因为,随着模型规模的扩大,计算和数据的相互作用不仅增强了模型的表达能力,还促使了更复杂的认知模式的涌现。然而,随着模型进入数万亿参数的阶段,智能提升的速度逐渐减缓,进入了所谓的“贤者时间”——一种能力提升停滞的阶段。
在这一阶段,扩展模型的规模似乎不会自动带来智能的飞跃。GPT-4.5的发布便是一个明显的例子:尽管它的参数达到了万亿级别,智能提升却没有呈现出GPT-3到GPT-4那样的巨大飞跃。
GPT-4.5的表现并不是Scaling Law的“死刑判决”,而是我们可能已经进入了另一个“贤者时间”。
想要超越当前的瓶颈,或许需要模型的规模扩展到50万亿参数,甚至更大的范围。在这个过程中,模型的涌现效应可能会再次爆发,带来智能的质变。
这也是为什么GPT-4.5的表现并不代表AI发展的“停滞”,而只是表明现有的Scaling Law开始遇到极限效应。从理论上讲,当大模型达到了某一“临界规模”,智能的飞跃必须依赖于架构的创新,而不仅仅是参数数量的增加。
规模扩张与算法模型优化这两条腿,需要走的更协调
上面我们提到过,大模型的发展是两条腿走路,前两年,主要靠Scaling Law着条腿在走,接下来,另一条腿需要多走两步了。
在大模型的技术发展中,Deepseek等公司为我们提供了一个至关重要的启示:模型的智能提升不仅仅依赖于规模的扩展,还可以通过精细的架构优化与算法创新,极大地提高效率和性能。Deepseek的成功并非单纯通过堆砌更多的计算资源,而是通过在算法和工程架构上的深度优化,实现了更高效的计算资源使用,使得模型的智能提升以更少的资源消耗达到了类似甚至更高的效果。这一切都表明,随着大模型规模的不断膨胀,计算资源的浪费和效率的低下将成为最重要的瓶颈。
通过减少冗余计算、优化数据流和调度方式,Deepseek能够在不依赖单纯增加计算量的前提下,提升模型的推理速度和响应效率。通过这种精细化优化,它使得模型能够在大规模计算资源的限制下,依然达到更高的智能水平。
这种方法将不仅推动技术的进步,还能大幅降低成本,提高大规模模型的可持续性与商业化潜力。Deepseek的成功表明,未来的大模型发展,将是效率和智能并行推进的过程,而不仅仅是规模的不断扩张。
然而,随着模型规模的进一步增大和效率优化的逐步实现,单纯依赖现有架构和算法已经无法突破Scaling Law的瓶颈。想要真正推动大模型智能的进一步提升,根本的技术创新,尤其是架构创新,必将成为未来突破的关键。
当前,Transformer架构被广泛应用于大规模语言模型中,其自注意力机制(self-attention)成功地处理了语言中的长程依赖问题,并在多种NLP任务中展现了超常表现。然而,随着模型规模的不断增加,Transformer的计算复杂度逐渐成为瓶颈,尤其是在处理长文本、极端大规模模型时,计算和内存的需求将变得极为庞大,限制了其应用的广度和深度。
未来的突破可能来自于一种比Transformer更高效的架构,这种新架构能够在保证智能水平的提升的同时,大幅降低计算复杂度和内存消耗。例如,稀疏化架构、图神经网络(GNN)以及混合模型架构(如结合强化学习与神经网络的混合架构)等,可能会成为新的方向。
这些新的架构设计将不仅提高模型的计算效率,还能帮助模型在推理过程中更好地处理多任务、跨模态信息,从而进一步增强其智能能力。例如,图神经网络在处理非欧几里得数据(如社交网络、分子结构等)时表现出色,未来或许可以通过这种方式处理更加复杂的数据结构,推动语言模型向更加泛化和多样化的能力发展。
因此,架构创新不仅仅是为了提高计算效率,更是为了从根本上推动模型智能的进一步升级,打破现有架构在大规模应用中的瓶颈,突破Scaling Law的限制。
展望未来,大模型的发展将不仅仅依赖单一的扩展路径,而是依靠两条腿并行走路:一方面,通过架构创新与算法优化来突破现有技术的瓶颈,另一方面,在算力和数据问题得到更好解决的基础上,继续扩展模型规模。这种双管齐下的方式,将为大模型的进一步智能提升提供坚实的基础。
来源:数智猿
刷新相关文章






















我要评论
不容错过的资讯









大家都在搜


