
DeepSeek要掀数据存储的“桌子”?
原创 一蓑烟雨 | 2025-02-28 21:34
【数据猿导读】 最近这几天,业界关注度最高的无疑是DeepSeek的几个开源项目,几乎每一个都会在该领域里带来一些惊喜。

最近这几天,业界关注度最高的无疑是DeepSeek的几个开源项目,几乎每一个都会在该领域里带来一些惊喜。
数据猿作为大数据领域的专业媒体,一直从数据层面来关注行业的进展。不得不说,在算法和算力层面很热闹,但相比之下,数据这个领域则要“冷清”很多。我们一直希望大模型的发展,能真是的带动大数据也腾飞一把。
所以,我们对DeepSeek最后一个开源项目尤为关注,因为这真的给数据领域带来了一个不小的惊喜。那这件事情到底会带来什么影响?
数据处理,成了整个“木桶”的短板
随着AI模型不断壮大,整个技术生态的痛点愈加显著。我们常常说,“大模型的训练就是一次彻底的折磨”——但真正的折磨,来自于数据处理,而非算力。今天,训练一个千亿甚至万亿参数的模大型,不仅需要海量数据,还需要在数据流动时极致的效率。
想象一下,你正在训练一个拥有数千亿参数的大模型,所需的训练数据可能多达数百TB,甚至更多。而这时,传统的分布式存储系统——如HDFS和NFS,已经完全无法跟上这种爆炸式增长的需求。它们就像老旧的高速公路,根本承载不住日益增多的车流。吞吐量太低、传输延迟太高,让数据流动几乎成了训练的“致命绊脚石”。
别看这些系统在小规模场景下还能应付,面对海量数据,它们的极限已经暴露。我们所期待的“加速”,往往在数据层的瓶颈面前,变成了空中楼阁。每一秒的延迟、每一次的数据访问堵塞,都直接影响着训练的速度和效果。想让一个超大规模模型训练迅速完成?你得先解开这道最难解的“数据瓶颈”。
推理阶段的“最后一公里”更致命!
可怕的并不只是训练阶段的数据延迟,推理阶段的延迟,才是致命的一击。很多人低估了推理时的“最后一公里”,认为只要模型训练好,推理就会顺利进行。错了!对于商业化应用来说,推理过程的延迟甚至比训练阶段更为关键。
以自动驾驶为例,1秒钟的推理延迟,足以让一辆车与另一辆车发生碰撞;而对于语音助手,1秒钟的迟钝反应,可能会直接影响到用户的使用体验,甚至让整个产品沦为“垃圾”。无论是在语音识别、图像处理,还是实时翻译等应用中,延迟是直接决定成败的命脉。
但现实是,现有的存储系统和数据传输架构,面对这些需求毫无能力应对。从存储设备到计算节点的每一次数据读写传输,都在不经意间增加延迟,让本应“瞬间响应”的推理任务成为了漫长的等待。而这些“无形的慢”恰恰让AI应用丧失了“瞬时反应”的本质。
想想那些闪烁在你眼前的AI应用——它们的每一秒钟,都在与死神赛跑。而数据流的迟滞,就是那颗随时可能爆发的“定时炸弹”。
如果我们说,数据存储和处理的低效性是AI进化中的“最大痛点”,那可绝不是危言耸听。AI行业的最大问题,不是缺少数据,也不是算力的不足,而是如何让这些海量数据以最快的速度流动。训练模型的每一秒钟延迟,推理请求的每一次拖延,都是整个AI应用无法迅速落地的核心障碍。
今天,每一个高端AI模型都在疯狂呼喊:“加速!”每一个推理请求都在期待:“快点返回结果!”然而,现实却依旧是——数据在原地打转,存储系统无能为力,数据传输的低效成了最致命的瓶颈。如果不解决这个问题,AI将永远停留在实验室阶段,永远无法突破到更广泛的商用应用。
但这条“路障”,究竟要怎样突破?
DeepSeek3FS,给我们送来了一个礼物
DeepSeek最新开源的3FS,作为一款开源分布式文件系统,主要解决了当前AI大模型训练和推理中的数据处理瓶颈问题。3FS通过利用现代硬件技术,特别是结合了固态硬盘(SSD)和远程直接内存访问(RDMA)技术,提供了比传统存储系统更高的吞吐量和更低的延迟,旨在提高AI大模型训练和推理的效率。

简而言之,3FS的核心目标是将数据访问提升到一个新的层次,通过大规模的并行存储架构与高效的网络协议,解决当前数据存储系统的性能瓶颈,确保在大规模数据集上能够快速高效地读取和写入。
性能是王道!不吹不擂,直接看看数据。
对于一款面向大规模数据处理的系统来说,性能是评价其价值的关键。3FS的性能表现非常突出,以下是其核心亮点:
1.6.6TiB/s的吞吐量
在实际应用中,3FS的性能表现堪称惊艳:
在180节点集群上,3FS实现了6.6TiB/s的聚合读取吞吐量,这一数据意味着你可以在不到一分钟的时间内处理近7TB的数据。
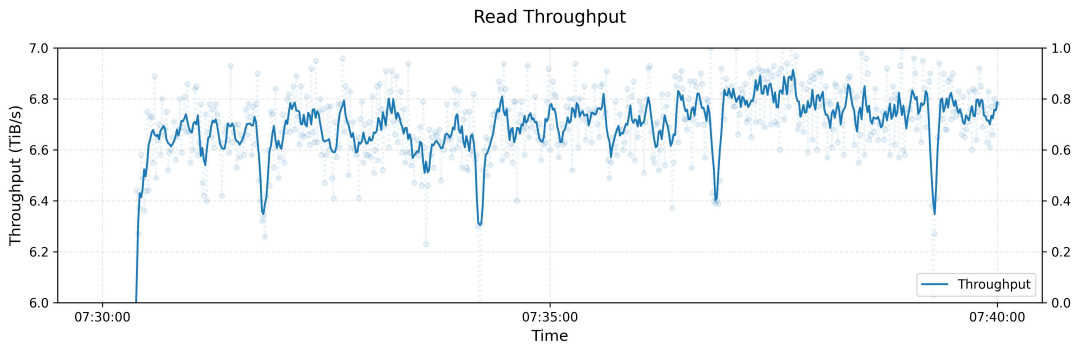
180节点集群上,3FS进行读取压力测试的吞吐量
在25节点的集群中,经过GraySort基准测试,3FS的吞吐量高达3.66TiB/min,远超传统存储系统的速度。
在KVCache查找时,3FS能够提供每个客户端节点40+GiB/s的峰值吞吐量,远超大多数现有数据处理平台的表现。
2.利用RDMA和SSD提高数据传输效率
远程直接内存访问(RDMA)技术的应用,是3FS性能提升的一个重要因素。RDMA能够让计算节点和存储节点之间进行直接的内存访问,从而消除了传统网络协议带来的延迟。这一技术使得存储和计算能够无缝连接,避免了常规网络通信中的瓶颈。此外,3FS结合了SSD存储的高速读写能力,进一步提高了数据访问的速度。
与传统网络协议相比,RDMA的低延迟特性能够在大规模并发访问时保持较高的传输速度,有效减小延迟,使得大规模并行计算任务能够更加高效地进行。
3.强一致性保证,简化开发
在分布式系统中,一致性问题常常是开发者面临的一大挑战。3FS通过实现强一致性语义,采用了链式复制(CRAQ)技术,确保了数据的一致性和高可用性。这一设计使得在高并发的环境下,开发者不需要过多担心数据同步和一致性问题,简化了开发难度。
强一致性的实现不仅保证了数据的准确性,也提高了系统的可靠性,对于AI模型训练和推理来说,能够有效避免由于数据不一致导致的错误和不稳定情况。
4.彻底的开源,重新拉平了起跑线
DeepSeek的3FS开源不仅仅是技术分享,它为全球开发者提供了一个全新的机会。3FS的开源意味着,无论是大公司还是小团队,都可以平等地使用这一革命性技术,推动AI应用的创新和发展。这种开放的态度无疑加速了整个AI行业的技术进步,也推动了AI商业化进程的加速。
通过开源,DeepSeek让这个强大的数据处理工具成为了AI社区的公共资产,让所有的开发者都能借助这一技术突破,实现更高效、更精准的AI应用。这也意味着,竞争不再只是资金和资源的比拼,更多的是技术的较量,谁能在数据处理上领先,谁就能在未来的AI战局中占据主导地位。
这么强的数据处理性能,意味着什么?
既然DeepSeek的3FS文件系统,大幅度提升了数据处理性能,那这会带来哪些改变呢?具体来看,可以从这几个角度来分析:
数据存储:谁能快,谁就能赢!
在AI的世界里,速度决定一切。而这份速度的“秘密武器”便是数据的处理能力。谁能让数据飞得更快,谁就能在这场技术竞赛中脱颖而出。DeepSeek的3FS文件系统,如同一辆极速跑车,突破了传统存储的桎梏,为AI的大规模应用打开了全新的可能性。想象一下,未来的医疗、金融、自动驾驶等行业,将依托3FS的超高速数据流畅性,实现一个前所未有的效率革命,真正实现AI的“即插即用”。
3FS的开源,意味着全球开发者将能够直接接入这一技术。你不再需要为数据延迟、存储瓶颈烦恼——所有的AI应用,从算法训练到推理执行,都可以以“秒级响应”的速度流畅运行。无论是临床诊断的实时反馈,还是自动驾驶的即时反应,3FS都能够为它们提供充足的动力。AI不再是理论上的“未来”,它已经步入了“实用”的阶段,而3FS无疑是这一进程的加速器。
大模型的规模化商用,开始提速了?
AI的商用化进程,一直被两大问题所困扰:高昂的计算成本和低效的数据处理能力。3FS通过极致的数据吞吐量和低延迟响应,解决了这一痛点。无论是智能助手、语音识别,还是自动驾驶,这些技术的商用落地都离不开高效的数据流转。
从这个角度看,3FS不再是简单的工具,它已经成为AI商用化的加速器。它帮助AI在短时间内完成训练、推理,降低了实时应用的响应延迟,为行业带来了前所未有的效率。未来的AI将不再是一些高大上的“实验室概念”,它会迅速走进我们的生活,带来更智能的城市、交通、医疗等服务。而3FS,则是这一切的技术保障之一。
云厂商需要注意了。
云计算平台的竞争,长期以来侧重于计算能力和存储容量的比拼。然而,真正的差异化竞争,未来将集中在存储和数据处理的效率上。3FS的出现,改变了这一格局。通过极高的吞吐量和超低延迟,3FS可能让云服务商的存储架构面临挑战——如果不能提供足够快的数据处理能力,云平台就很难在未来的AI竞争中占有一席之地。
想一想,谁能在未来的云计算市场中占据优势?不仅仅要存储容量更大、计算能力更强,还要为客户提供超高数据吞吐量和零延迟服务的“数据管道”。这意味着,未来的云平台,存储能力和数据处理速度将成为竞争的核心,甚至是决定胜负的关键。
数据存储厂商应该如何应对?
随着AI技术日益壮大,尤其是大模型的崛起,数据存储成为决定未来AI应用能否商业化的关键环节。DeepSeek的3FS系统通过打破传统存储瓶颈,展示了超高吞吐量和低延迟在数据处理中的革命性作用。这一技术突破不仅代表了存储领域的一次重大创新,也意味着存储厂商正站在了一个新的战略交汇点。
对于数据存储厂商,无论是软件厂商还是硬件厂商,3FS的开源无疑是一个强烈的信号,标志着未来存储技术的核心竞争力不再是单纯的存储容量,而是数据传输的速度、吞吐量与低延迟。如何快速响应AI时代的需求,已经不再是一个选择,而是生死存亡的关键。
>软件存储厂商:角色需要从“存储容器”向“数据高速公路”转变
对于软件厂商来说,这意味着需要从根本上重新设计存储架构,从“存储容器”向“数据高速公路”转变。传统的存储系统,尤其是像HDFS这样的架构,已经无法满足大规模AI训练和推理对数据处理的需求。现有的系统无法实现与现代硬件设备,尤其是SSD和RDMA技术的深度整合,导致吞吐量、延迟等性能瓶颈的长期存在。要想在这个变革中脱颖而出,软件厂商必须在高吞吐量、低延迟以及强一致性方面进行持续的技术突破,打造能够支持AI大规模训练和推理的下一代存储系统。
但这不仅仅是技术上的突破,更是对存储理念的颠覆。在AI时代,存储系统不再只是被动的“数据保管员”,它必须成为一个高效的数据处理引擎,能够实现几乎实时的数据读取和写入。存储厂商需要认识到,传统的存储架构和方法已逐渐显得力不从心,只有真正解决了数据处理瓶颈,才能让AI的“计算力”在全球范围内真正得到释放。
>硬件厂商:从“硬盘堆砌”到“系统协同”
对于硬件厂商而言,3FS展现的并非只是一个“存储需求”的挑战,而是一个硬件与软件深度协同的时代。传统硬盘厂商长期依赖的存储系统优化,已无法适应AI时代对吞吐量和低延迟的严苛要求。SSD和RDMA的结合是硬件领域的一次技术探索,但硬件厂商需要在网络架构、存储介质以及计算节点之间实现更加无缝的协同。
这意味着,硬件厂商必须将焦点从单纯提升存储介质的容量和速度,转向优化硬件与存储系统之间的协同工作,实现从存储设备到计算节点的全面加速。只有这样,才能迎接AI大模型所带来的海量数据吞吐需求,打造出未来的“数据高速公路”。
而且,硬件厂商应当预见到,AI的应用场景将推动更为定制化的硬件解决方案需求。大规模数据中心、超算平台以及高性能计算应用,将要求硬件能够在同一平台上处理数十甚至上百TB的数据,而这些数据需要被极速处理和存取。硬件厂商如果能够从“应用场景”出发,设计出针对性强的硬件解决方案,就能在竞争激烈的市场中占得先机。比如,为了应对AI训练和推理过程中极大的并行数据访问需求,硬件厂商可以设计出支持高带宽、低延迟的网络硬件,在计算和存储之间实现更高效的“高速通道”。
对于云计算平台而言,存储能力将成为未来竞争的决定性因素。传统云平台的存储架构已逐渐暴露出其瓶颈,如何在处理大规模AI训练数据时提供高吞吐量和低延迟的存储能力,已经成为平台服务商无法忽视的关键问题。未来,谁能将数据处理能力做到极致,谁就能抢占AI应用的先机。因此,存储厂商若能顺应这一趋势,早早在产品设计中就与云计算平台深度合作,进行技术整合,必定能够在激烈的市场竞争中占据有利位置。
诚然,3FS让我们看到了数据存储和处理的巨大潜力,但要真正使其成为AI商业化的“杀手锏”,仍然面临着巨大的挑战。大规模数据的存储、流动和处理将不仅仅是技术的较量,还将成为云平台、硬件厂商乃至AI开发者之间的竞争焦点。谁能够更高效地处理和存储数据,谁就能在未来的AI产业中占得先机,获得更多的市场份额。
总之,3FS无疑是AI产业中的一次重大技术突破,但它能否持续推动AI行业走向成熟,能否成为商用化落地的“催化剂”,依然需要我们用更长远的视角来观察。未来的AI产业,将是技术与商业双重驱动的市场,而数据处理和存储技术,势必将在这个过程中发挥着越来越重要的作用。
来源:数据猿
































































































我要评论
不容错过的资讯








大家都在搜


