
【AI大模型展】博文大模型——专注于服务和营销领域,更专业,更有温度
追一科技 | 2024-06-28 21:31
【数据猿导读】 追一博文大模型,除了拥有基础大模型的通用能力外,还通过NL2X等技术准确将企业知识融入,并针对与客户场景强相关的,如对话分析、对话交互等专项能力进行加强,以便达到更好、更稳定的最终业务效果。

博文大模型
该AI大模型由追一科技投递并参与数据猿与上海大数据联盟联合推出的《2024中国数据智能产业AI大模型先锋企业》榜单/奖项”评选。
追一博文大模型,除了拥有基础大模型的通用能力外,还通过NL2X等技术准确将企业知识融入,并针对与客户场景强相关的,如对话分析、对话交互等专项能力进行加强,以便达到更好、更稳定的最终业务效果。
因此,在博文模型基础上,追一进一步研发了一套 LLM Agent 框架,赋予博文"记忆”和"行动”,一方面通过 Agent 框架将思维链的工作机制固化下来,从而将思维链的能力充分发挥。另一方面,解决幻觉问题,更好实现LLM 的知识可控、能力可控、业务逻辑可控,同时知识更新、能力扩展更加高效。在 LLM Agent 框架的基础之上,支持复杂任务场景下任务拆解,以 Multi-Agents协同工作的方式,实现企业复杂业务场景上的最优表现。
应用场景/使用群体
银行:分期营销、开户营销、促活营销、风险管理、权益提醒等营销与客服场景
保险:赠转销、续费提醒、分期产品续保、现场勘查回访、短险转长险、新契约回访、小额保险推销
券商:新客理财营销、创业板回访、新客回访、开户营销、新股中签缴款、适当性回访、风险测评
政务:市民服务、市长热线、社区金融、党建宣传、税务咨询、政策助手、智慧交通.
产品功能
博文除了具备通用大模型具备的文本生成、代码生成、逻辑推理、文学创作等能力外,还通过NL2X等技术将企业知识融入,并针对与客户场景强相关的,如对话分析、对话交互等专项能力进行加强,以便达到更好、更稳定的最终业务效果。
其能力如下:
1、对话交互,解决业务咨询与办理问题,实现用户自助服务,其具备单轮和多轮对话能力,从容应对任务办理、业务咨询、寒暄等对话场景,并在交互中具备共情能力
2、针对复杂问题的意图理解和可控生成。
3、对话分析,挖掘企业服务和营销过程里积累的语音和文本对话数据,自动抽取客户意图和特征,实现智能分析,可应用于会话质检、会话总结等,并生成业务报告,进行营销预测。
4、知识注入,积累的搜索和NL2X技术让专业知识召回更精准。
产品优势
1. 百亿级参数模型,体量更小,训练过程和推理速度更快,成本更低。
2. 拥有更垂直适用的任务能力,并非通用式的聊天,可适配具体行业业务场景中的任务,如金融、政务领域中的咨询服务、文案生成、专家决策等。
3. 在知识能力上,更有领域纵深优势,且保证即时性。
4. 支持私有化部署,对于金融、运营商等垂直行业的特定场景来说是必要的,保证数据安全的同时,还能更灵活地去应对业务场景。
技术说明
在自研大模型技术过程中,追一科技分别在位置编码、长视野、优化器等核心技术尝试创新,并获得国内外广泛关注和应用。
A.Roformer——基于RoPE升级的Transformer
追一科技的Roformer模型采用了自研的旋转位置编码,进一步提升了目前主流Transformer架构模型的能力。该技术公开后获得国内外业内的广泛关注。
RoPE,旋转式位置编码(Rotary Position Embedding),核心思想是将文本中两个字符的之间相对位置用角度来表示,这样的好处是在transformer结构的模型中注意力的计算要计算两个向量的内积,而采用角度表示相对位置距离,则这个内积正好体现了相对位置之间的大小。这种巧妙的设计方式天然契合transformer的注意力机制,带来更好的编码能力。
一般来说,绝对位置编码具有实现简单、计算速度快等优点,而相对位置编码则直接地体现了相对位置信号,跟我们的直观理解吻合,实际性能往往也更好。于是RoPE就集各家之所长,提出通过绝对位置编码的方式实现相对位置编码的旋转式位置编码。
Roformer 模型是transformer 的升级版,它的主要改动是应用了“旋转式位置编码(Rotary Position Embedding,RoPE)”代替 transformer 中的绝对位置编码,这是一种配合 Attention 机制能达到“绝对位置编码的方式实现相对位置编码”的设计。
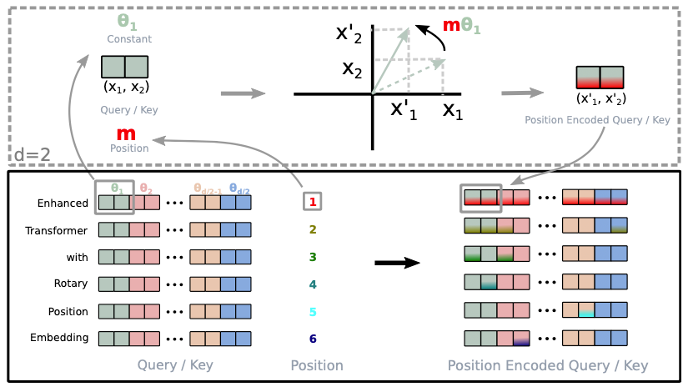
当前主流知名大模型,公开模型细节的,基本都将RoPE作为标准配置,是追一科技对大模型研究领域重要贡献。下面是部分知名大模型的引用情况:
- Google 的 PaLM,以及PaLM2模型的采用

- META 的 LLaMA,以及衍生Alpaca、Vicuna模型的采用

- EleutherAI的GPT-NeoX-20B,以及OpenChatKit模型的采用

- 清华大学GLM、以及ChatGLM模型的采用

- 微信 WeLM模型的采用

B.NBCE——无限扩大模型视野
大模型基于注意力机制,注意力范围也就是大模型的“视野”,这也是大模型发挥效果的关键能力之一,广阔的“视野”可以让大模型具备更强的上下文理解能力。由于底层技术的局限性,导致现在所有大模型输入输出的文本长度都有上限,即大模型“视野”有限。大模型的视野在训练阶段就已经固化下来,2倍的视野长度,意味着4倍的成本。且视野长度依然是有上限的。
追一科技提出了一种新的方便快捷、即插即用的无限扩展大模型(LLM)输入长度的方法,它适配任意一种模型结构,不需要更改模型结构,不需要重新训练模型,就能直接使用。这种方法基于朴素贝叶斯,因此我们将它命名为NBCE(Naive Bayes-based Context Extension)。它的核心思路是将输入的长文本切分为若干部分,配上输入的指令,在条件独立的假设下利用朴素贝叶斯对生成的内容进行采样,再通过投票方式确定输出。
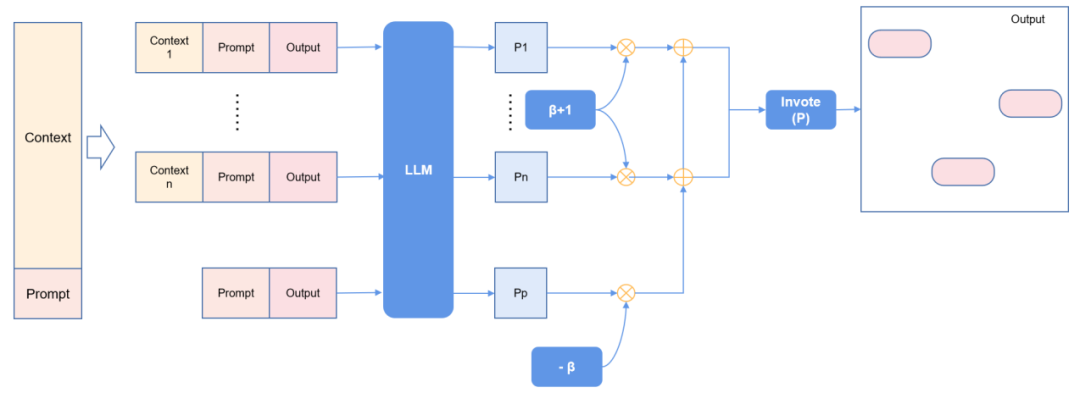
NBCE不需要对模型进行修改,也不需要进行训练或者微调。此外,NBCE方法是与模型无关的,这代表目前所有的模型能够直接使用,同时理论上只要在计算资源允许的范围内,通过NBCE方法就可以将模型扩展到无限长度。下面是一个示例:

C.Tiger优化器——降低训练成本
大模型训练成本高,显存是主要瓶颈之一。其中训练过程中的大部分显存消耗发生在优化器。当前业界最常用的AdamW优化器,一阶矩和二阶矩占用了大量显存,追一科技提出的Tiger优化器对此进行了简化替换,得到的训练效果指标与AdamW持平,但是整体显存消耗下降25%~30%。
D.数据积累
追一技术团队过去有丰富的搜索引擎开发经验,积累了丰富的数据治理经验,包括爬虫正文抽取、反垃圾、质量因子、文章分类、排重等。积累了数十T的高质量公开数据。
追一科技过去多年项目实施经历,建设数据操作台和数据运营台,降低项目上数据生产的成本的同时,也积累了大量独有行业数据,包括大于100G的人人对话人机对话数据、至少40G带标签的行业数据。
追一科技参加各种NLP比赛、榜单、同业交流,积累了大于30G的带标注的NLP任务数据,包括机器翻译、IE、QA、WSD、NLI、MRC、NL2SQL、情感分析、因果推理、数学应用等任务的标注数据。
以上数据用于训练LLM获得独有优势。
服务客户
中国工商银行、招商银行、浦发银行、中国人民保险、中金公司、国投证券、大连市税务局。
关于企业
·追一科技
追一科技是一家致力成就客户价值的领先 NLP 人工智能公司与 AI 员工解决方案提供商,拥有自研的领域大模型「追一博文」,并拓展到智能语音多模态的 A I全栈技术。
公司累计服务超过 300 家中大型企业/政府类客户,助力客户在服务、营销,运营等多个场景上实现智能化转型升级。2023年7月,追一科技获得国家级专精特新“小巨人”企业称号。目前,公司在深圳、上海、北京、成都等地均有专业服务团队。
★以上由追一科技投递申报的项目案例,最终将会角逐由数据猿与上海大数据联盟联合推出的《2024中国数据智能产业AI大模型先锋企业》榜单/奖项。
该榜单奖项最终将于7月24日以下活动中进行榜单的首发与奖项的颁发,欢迎报名莅临现场:
来源:追一科技 数据猿








































我要评论
不容错过的资讯















大家都在搜



